
If you've been following the rapid evolution of AI, you may have noticed a shift happening right under our noses: it's no longer just about building bigger and bigger language models. On the contrary, major players such as OpenAI and Google are now focusing on the so-called real-time calculationThis is an elegant way of saying "give an AI model more time to think" whenever it is confronted with a tricky question.

OpenAI scale toward 'Human-Level' problem solving
This new direction stems from a simple observation: the scaling gigantic models has a limit. Not only does it become too costlyIn other words, we may have reached a point where blindly introducing more data and parameters leads to less and less satisfactory results. In other words, we may have reached a point where blindly introducing more data and parameters yields less and less satisfactory results. This is where real-time computing comes in: a strategy that allows a model to pause, execute multiple solution paths, reflect and refine its answer on the fly.
1. A new era for reasoning AI
Some advanced systems, such as OpenAI's "Strawberry family" (e.g. models o1 and o3), illustrate real-time computing in action. Often described as "thinking models", these systems can handle problems that seem as difficult as doctoral-level mathematics or cutting-edge scientific research, precisely because they perform real-time reasoning. They are designed to take several steps rather than just the first thing that comes to mind.
If you've ever tackled a big puzzle, such as working out a complex formula on a spreadsheet or solving a word problem, you probably didn't do it all at once. You reasoned step by step, clarifying constraints, trying out a possible solution, spotting errors and then revising. That's exactly the approach these advanced AI systems are taking today: they look for different potential solutions, evaluate them and refine their approach until they arrive at the final answer.
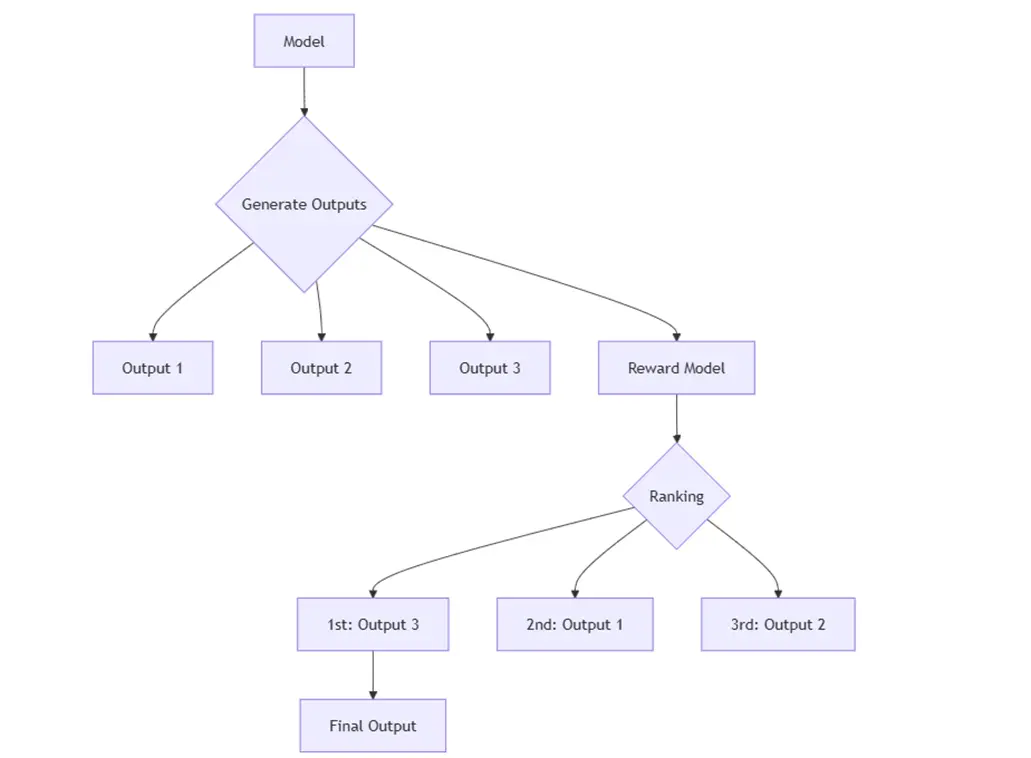
Reward Model during chain-of-thought reasoning
2. Four fundamental elements of "reflection" models
Researchers studying OpenAI's o1 and o3 models, as well as Google's "Gemini" model, highlight four essential ingredients for true real-time computing:
- Policy initialization - This is everything the model "knows" before you ask it a question, from its general knowledge acquired in pre-training (such as reading large amounts of text) to its final tuning. This initial policy determines how the AI will "think", including its ability to clarify complex questions, propose alternative solutions or correct itself when it realizes something is wrong.
- Reward design - Just as you might give a gold star to a child for a correct answer, a model needs feedback to know which approaches are right or wrong. If you're playing chess, it's easy: you win or you lose. But for language and reasoning tasks, the "right" answer can be more nuanced. Researchers are therefore designing reward models which guide the AI, step by step, towards the best solution, sometimes rewarding partial accuracy along the way.
- Search - Instead of generating a single answer, AI can "branch out" and explore several possible solutions in parallel (a technique akin to tree search) or continuously refine a solution through iterative revisions. If the first attempts at a solution are unsatisfactory, the model can pivot and take another route.
- Apprenticeship - Finally, the best "thinking" models don't just search blindly; they learn from each attempt. Whereas traditional large language models rely heavily on pre-collected datasets, "thinking" models often use thereinforcement learning during or after inference to refine their approach. The more they interact with an environment or systematically check their solutions, the more they improve, all without the need for an army of human labelers.
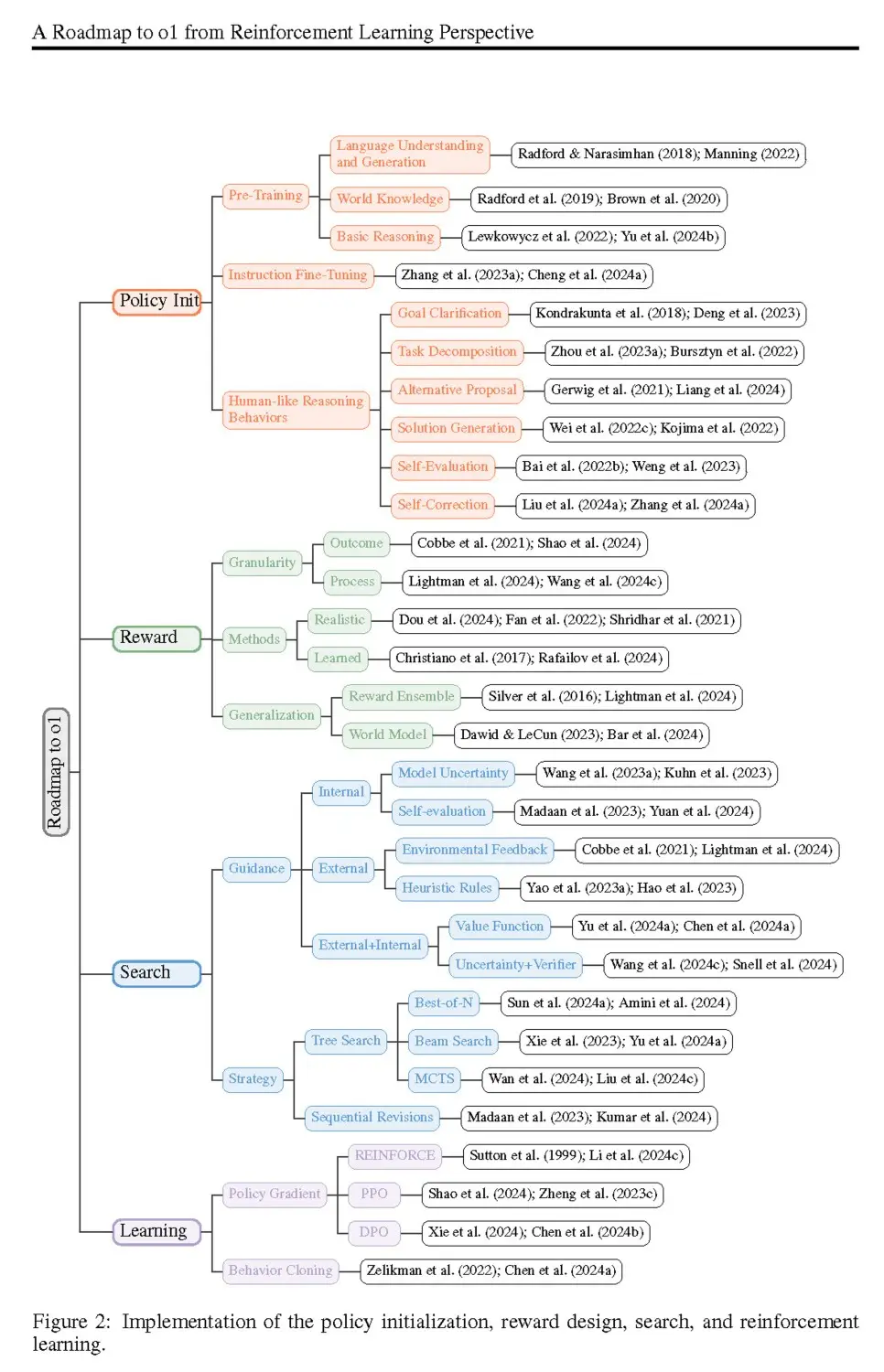
Building blocks of o1 " thinking " model
3. Open template o1
In a publication by Fudan University and Shanghai AI Laboratory researchers dissect how OpenAI's o1 (and by extension, o3) achieves its advanced reasoning prowess. They methodically review each of the four elements - policy initialization, reward design, search and learning - and explain how they combine to give these models "AGI-like" problem-solving capabilities.
One of the main conclusions is that real-time calculation is not only useful for solving tricky mathematical or logical problems; it also opens the way to a potential "world model", in which AI can understand and navigate more abstract domains. The Fudan team suggests that by carefully orchestrating each stage of the search and offering partial rewards, it is possible to replicate many of the "thinking" behaviors observed in advanced closed-source models. Their ultimate goal? To make this know-how available to everyone, so that small labs and start-ups can experiment with their own versions of o1-like models.
4. Where real-time computing meets the "age of discovery
So what next?
- Smarter multimodal models - The Fudan researchers note that combining text, images and even video helps a model build a more accurate "model of the world". Imagine an AI able to watch a short clip, interpret it, then apply the same reasoning it uses for text.
- More open-source tools - As more and more teams replicate these techniques, we'll see a wave of open-source "thinking" models that small companies or even hobbyists can tweak. This could democratize advanced AI, making it less about who has the biggest data center and more about who can innovate inference techniques.
- Further exploration of reinforcement learning - Reinforcement learning at the scale of real-time interaction is set to grow, as it doesn't rely on infinitely labeled data. This means that we will increasingly see AI systems discover brand-new strategies (such as AlphaGo's "move 37") that human experts would never have imagined.
Ultimately, real-time computing rewrites the rules for AI scaling. By letting models "think longer", we unlock more robust reasoning without forcing them to become huge black boxes. This shift to a more human-like problem-solving strategy is a source of inspiration. After all, many of us remember teachers telling us to "show our work" in math class. Today, AI is doing something similar, and it's paying off in leaps and bounds.
On the corporate side
For businesses, the rise of "thinking" AI models powered by real-time calculations has immediate and far-reaching implications:
- Extended use cases - With the ability to tackle far more complex and advanced tasks, these models can drive automation and decision-making across a wider spectrum of business processes - from sophisticated data analytics to nuanced customer interactions. The potential extends far beyond the classic chatbot, opening up new avenues for innovation and operational efficiency.
- Compromise in terms of performance and cost - The very nature of real-time computing means that the model takes additional steps during inference - sometimes adding seconds or even up to a minute to get a final answer. In addition to longer response times, each step generates more tokens, which increases financial and energy costs. As technology evolves, these overheads may decrease, but companies still need to take into account increased operational expenses and potential throughput bottlenecks.
- Explicability and transparency - Longer chains of reasoning can, in principle, be used to understand how the model arrives at certain conclusions. However, full visibility of these intermediate steps is not always possible, especially in some closed-source configurations. On the other hand, open-source initiatives are already showing promise in providing a deeper insight into the reasoning flow, helping organizations to build trust and compliance by making AI "decisions" more transparent.
- Increased risk of hallucinations - Iterative thinking can sometimes amplify "hallucinations", when a model inadvertently fabricates facts. Companies need robust testing and supervision to limit errors, especially in mission-critical applications. Continuous improvement of model feedback loops and evaluation metrics can help reduce these missteps over time.
Overall, the he adoption of real-time computing requires a balanced assessment of costs, performance and explainability.. However, for those willing to invest in this technology, the payoff lies in a new class of artificial intelligence systems capable of solving problems once deemed too complex for automated solutions.
Conclusion
From OpenAI's o1 and o3 projects to the latest Chinese research, a clear pattern is emerging: real-time computing is the new frontier: By combining policy initialization, carefully crafted rewards, sophisticated search strategies and continuous learning, AI models can behave more like true problem solvers than rote memorization engines..
As we move fully into the Age of Discovery, we can expect new possibilities for AI to interact with the world, with reasoning on a level once considered impossible. Whether solving complex scientific questions, contributing to creative projects or helping companies automate tasks, "thinking" models promise to transform AI from a mere autocomplete to a true partner in innovation.
The future, it seems, n'belongs to not onlyà larger models, but also smarter models- machines that know how to stop, reconsider and explore multiple avenues in search of something new. This proves what many educators have always believed: taking your time to think is the best way to get the right answer in the end. And it turns out that this is just as true for AI as it is for us humans.
By Jérémy BRON, AI Director, Silamir Group
Sources
- Test Time Compute (2024, December 13). Cloud Security Alliance Blog. Retrieved from https://cloudsecurityalliance.org/blog/2024/12/13/test-time-compute#
- Zeng, Z., Cheng, Q., Yin, Z., Wang, B., Li, S., Zhou, Y., Guo, Q., Huang, X., & Qiu, X. (2024, Dec 18). Scaling of Search and Learning: A Roadmap to Reproduce o1 from Reinforcement Learning Perspective. Fudan University & Shanghai AI Laboratory. Retrieved from https://arxiv.org/pdf/2412.14135
- OpenAI Scale Ranks Progress Toward 'Human-Level' Problem Solving (2024, July 11). Bloomberg. Retrieved from https://www.bloomberg.com/news/articles/2024-07-11/openai-sets-levels-to-track-progress-toward-superintelligent-ai?embedded-checkout=true


