

Cette nouvelle orientation découle d’une constatation simple : la mise à l’échelle de modèles de taille gigantesque a une limite. Non seulement elle devient trop coûteuse, mais elle ne permet pas non plus d’obtenir les améliorations spectaculaires que nous avons connues dans les premiers temps des grands modèles de langage. En d’autres termes, il se peut que nous soyons arrivés à un point où le fait d’introduire aveuglément davantage de données et de paramètres donne des résultats de moins en moins satisfaisants. C’est là qu’intervient le calcul en temps réel : une stratégie qui permet à un modèle de faire une pause, d’exécuter plusieurs chemins de solution, de réfléchir et d’affiner sa réponse à la volée.
| Critère | Scaling classique | Test-time compute |
|---|---|---|
| Levier de performance | Plus de données et de paramètres | Plus de temps de calcul au moment de la réponse |
| Moment de l’effort | À l’entraînement (pré-entraînement) | À l’inférence (au moment de la question) |
| Méthode de raisonnement | Réponse en une seule passe | Étapes multiples : explorer, évaluer, corriger |
| Limite principale | Coût croissant, rendements décroissants | Temps de réponse et coût par requête plus élevés |
| Exemples de modèles | LLM génériques de génération précédente | OpenAI o1 / o3, Google Gemini |
| Analogie | Répondre du tac au tac | « Montrer son raisonnement », comme en cours de maths |
« Ce basculement d’un levier (la taille) vers un autre (le temps de réflexion) structure toute la suite de cet article. »
1. Une nouvelle ère pour l’IA de raisonnement
Certains systèmes avancés, tels que la « famille Strawberry » d’OpenAI (par exemple, les modèles o1 et o3), illustrent le calcul en temps réel en action. Souvent décrits comme des « modèles de réflexion », ces systèmes peuvent traiter des problèmes qui semblent aussi difficiles que des mathématiques de niveau doctoral ou des recherches scientifiques de pointe, précisément parce qu’ils effectuent un raisonnement en temps réel. Ils sont conçus pour prendre plusieurs mesures plutôt que de se contenter de la première chose qui leur vient à l’esprit. Si vous vous êtes déjà attaqué à une grande énigme, par exemple l’élaboration d’une formule complexe sur une feuille de calcul ou la résolution d’un problème de mots, vous ne l’avez probablement pas fait d’un seul coup. Vous avez raisonné étape par étape, en clarifiant les contraintes, en essayant une solution possible, en repérant les erreurs, puis en révisant. C’est exactement l’approche qu’adoptent aujourd’hui ces systèmes d’IA avancés : ils recherchent différentes solutions potentielles, les évaluent et affinent leur approche jusqu’à ce qu’ils parviennent à la réponse finale.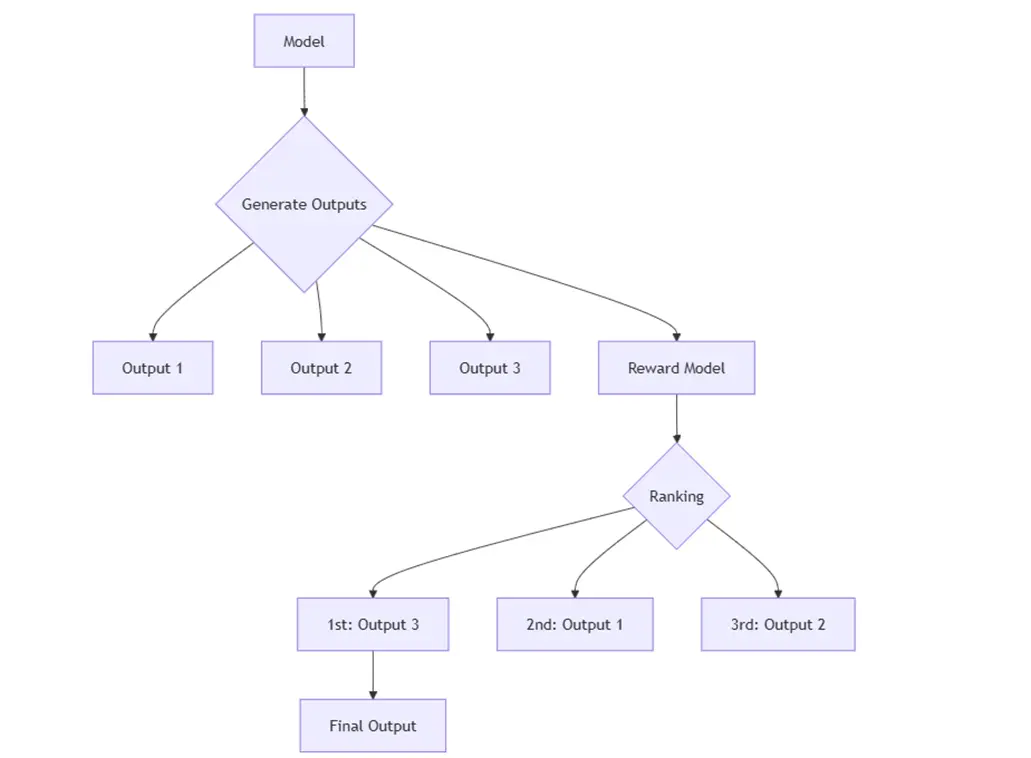
2. Quatre éléments fondamentaux des modèles de « réflexion »
Les chercheurs qui étudient les modèles o1 et o3 d’OpenAI, ainsi que le modèle « Gemini » de Google, mettent en évidence quatre ingrédients essentiels pour un véritable calcul en temps réel :
-
- Initialisation de la politique – Il s’agit de tout ce que le modèle « sait » avant que vous ne lui posiez une question, qu’il s’agisse de ses connaissances générales acquises lors du pré-entraînement (comme la lecture de grandes quantités de texte) ou de sa mise au point finale. Cette politique initiale détermine la manière dont l’IA « pensera », y compris sa capacité à clarifier des questions complexes, à proposer des solutions alternatives ou à se corriger lorsqu’elle se rend compte que quelque chose ne va pas.
-
- Conception des récompenses – Tout comme vous pourriez donner une étoile d’or à un enfant pour une réponse correcte, un modèle a besoin d’un retour d’information pour savoir quelles approches sont bonnes ou mauvaises. Si vous jouez aux échecs, c’est facile : vous gagnez ou vous perdez. Mais pour les tâches de langage et de raisonnement, la « bonne » réponse peut être plus nuancée. Les chercheurs conçoivent donc des modèles de récompense qui guident l’IA, étape par étape, vers la meilleure solution, en récompensant parfois l’exactitude partielle en cours de route.
-
- Recherche – Au lieu de générer une réponse unique, l’IA peut « se ramifier » et explorer plusieurs solutions possibles en parallèle (une technique proche de la recherche arborescente) ou affiner continuellement une solution par le biais de révisions itératives. Si les premières tentatives de solution ne sont pas satisfaisantes, le modèle peut pivoter et emprunter une autre voie.
-
- Apprentissage – Enfin, les meilleurs modèles « pensants » ne se contentent pas d’effectuer des recherches à l’aveuglette ; ils tirent des enseignements de chaque tentative. Alors que les grands modèles de langage traditionnels s’appuient fortement sur des ensembles de données pré-collectées, les modèles « pensants » utilisent souvent l’apprentissage par renforcement pendant ou après l’inférence pour affiner leur approche. Plus ils interagissent avec un environnement ou vérifient systématiquement leurs solutions, plus ils s’améliorent, le tout sans avoir besoin d’une armée d’étiqueteurs humains.
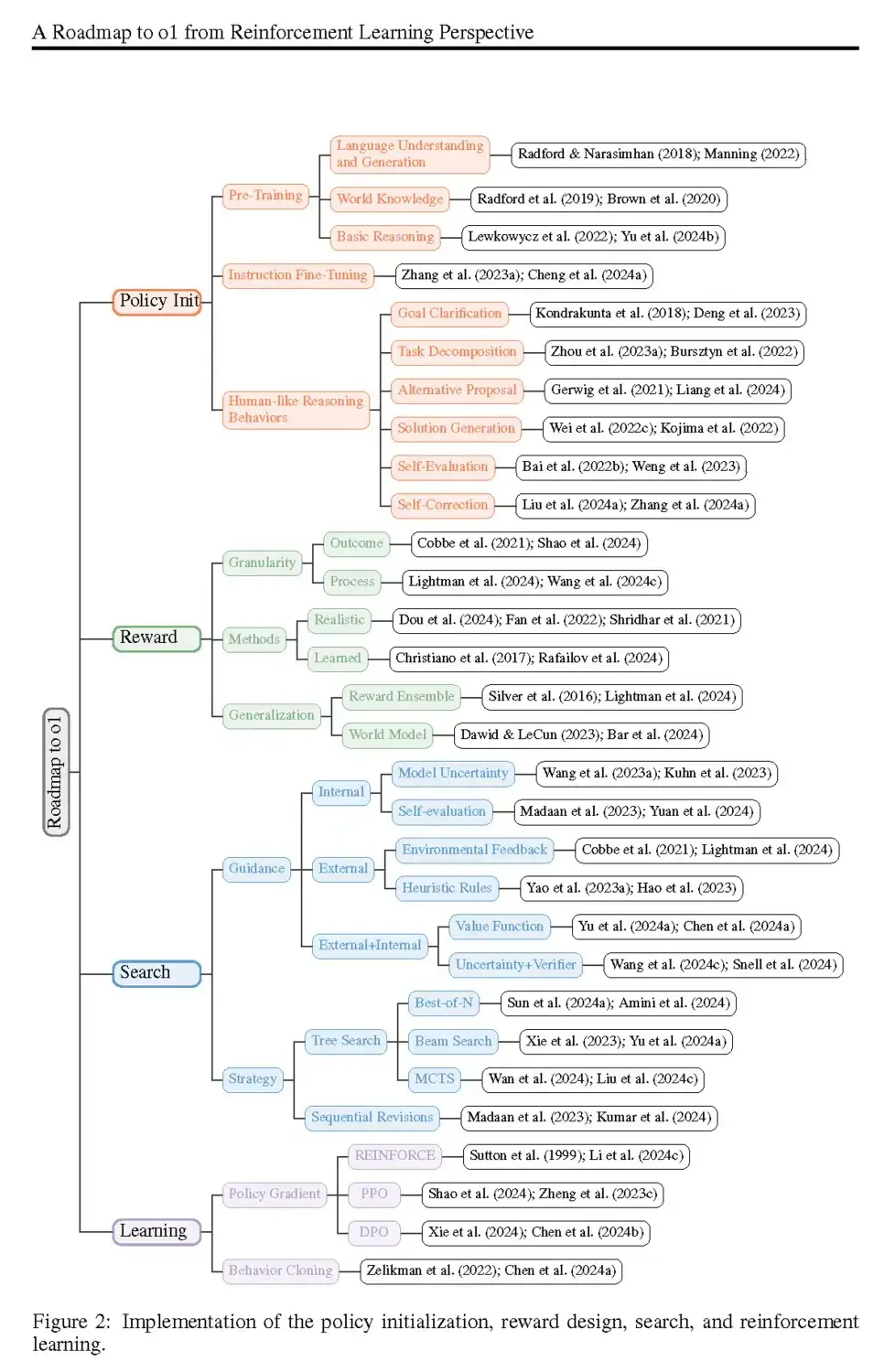 Building blocks of o1 « thinking » model
Building blocks of o1 « thinking » model
3. Ouvrir le modèle o1
Dans une publication de l’ Université de Fudan et du Shanghai AI Laboratory , des chercheurs dissèquent la manière dont o1 d’OpenAI (et par extension, o3) accomplit ses prouesses en matière de raisonnement avancé. Ils passent méthodiquement en revue chacun des quatre éléments – initialisation de la politique, conception de la récompense, recherche et apprentissage – et expliquent comment ils se combinent pour donner à ces modèles des capacités de résolution de problèmes « semblables à celles de l’AGI ». L’une des principales conclusions est que le calcul en temps réel n’est pas seulement utile pour résoudre des problèmes mathématiques ou logiques délicats ; il ouvre également la voie à un « modèle de monde » potentiel, dans lequel l’IA peut comprendre et naviguer dans des domaines plus abstraits. L’équipe de Fudan suggère qu’en orchestrant soigneusement chaque étape de la recherche et en offrant des récompenses partielles, il est possible de reproduire bon nombre des comportements de « réflexion » observés dans les modèles avancés à source fermée. Leur objectif ultime ? Mettre ce savoir-faire à la disposition de tous, afin que les petits laboratoires et les jeunes entreprises puissent expérimenter leurs propres versions de modèles semblables à l’o1.4. Le point de rencontre entre le calcul en temps réel et « l’ère de la découverte »
Alors, quelle est la prochaine étape ?
-
- Des modèles multimodaux plus intelligents – Les chercheurs de Fudan notent que la combinaison de textes, d’images et même de vidéos aide un modèle à construire un « modèle du monde » plus précis. Imaginez une IA capable de regarder un court clip, de l’interpréter, puis d’appliquer le même raisonnement que celui qu’elle utilise pour le texte.
-
- Davantage d’outils open-source – À mesure que de plus en plus d’équipes reproduiront ces techniques, nous assisterons à une vague de modèles de « réflexion » open-source que les petites entreprises ou même les amateurs pourront peaufiner. Cela pourrait démocratiser l’IA avancée, en faisant en sorte qu’il s’agisse moins de savoir qui possède le plus grand centre de données que de savoir qui peut innover en matière de techniques d’inférence.
-
- Exploration plus approfondie de l’apprentissage par renforcement – L’apprentissage par renforcement à l’échelle de l’interaction en temps réel est appelé à se développer, car il ne repose pas sur des données étiquetées à l’infini. Cela signifie que nous verrons de plus en plus de systèmes d’IA découvrir de toutes nouvelles stratégies (comme le « move 37 » d’AlphaGo) que les experts humains n’auraient jamais imaginées.
En fin de compte, le calcul en temps réel réécrit les règles de mise à l’échelle de l’IA. En laissant les modèles « réfléchir plus longtemps », nous débloquons des raisonnements plus robustes sans les forcer à devenir d’énormes boîtes noires. Ce passage à une stratégie de résolution des problèmes plus proche de celle des humains est une source d’inspiration. Après tout, beaucoup d’entre nous se souviennent de professeurs qui leur disaient de « montrer leur travail » en cours de mathématiques. Aujourd’hui, l’IA fait quelque chose de similaire, et cela porte ses fruits à pas de géant.
Du côté des entreprises
Pour les entreprises, l’essor de modèles d’IA « pensants » alimentés par des calculs en temps réel a des implications immédiates et profondes :
-
- Cas d’usages élargis – Avec la capacité de s’attaquer à des tâches beaucoup plus complexes et avancées, ces modèles peuvent favoriser l’automatisation et la prise de décision dans un spectre plus large de processus d’entreprise – des analyses de données sophistiquées aux interactions nuancées avec les clients. Le potentiel s’étend bien au-delà du chatbot classique, ouvrant de nouvelles voies à l’innovation et à l’efficacité opérationnelle.
-
- Compromis en termes de performances et de coûts – La nature même du calcul en temps réel signifie que le modèle prend des mesures supplémentaires au cours de l’inférence – parfois en ajoutant des secondes ou même jusqu’à une minute pour obtenir une réponse finale. En plus des temps de réponse plus longs, chaque étape génère plus de jetons, ce qui augmente les coûts financiers et énergétiques. Avec l’évolution de la technologie, ces frais généraux pourraient diminuer, mais les entreprises doivent toujours tenir compte de l’augmentation des dépenses opérationnelles et des goulets d’étranglement potentiels au niveau du débit.
-
- Explicabilité et transparence – Des chaînes de raisonnement plus longues peuvent, en principe, permettre de comprendre comment le modèle parvient à certaines conclusions. Cependant, il n’est pas toujours possible d’avoir une visibilité totale sur ces étapes intermédiaires, en particulier dans certaines configurations à code source fermé. En revanche, les initiatives open-source sont déjà prometteuses car elles offrent une vision plus approfondie du flux de raisonnement, aidant ainsi les organisations à renforcer la confiance et la conformité en rendant les « décisions » de l’IA plus transparentes.
-
- Risques accrus d’hallucinations – La pensée itérative peut parfois amplifier les « hallucinations », lorsqu’un modèle fabrique des faits par inadvertance. Les entreprises ont besoin de tests et d’une supervision solides pour limiter les erreurs, en particulier dans les applications critiques. L’amélioration continue des boucles de rétroaction des modèles et des mesures d’évaluation peut contribuer à réduire ces faux pas au fil du temps.
Dans l’ensemble, l ‘adoption du calcul en temps réel nécessite une évaluation équilibrée des coûts, des performances et de l’explicabilité. Cependant, pour ceux qui sont prêts à investir dans cette technologie, le gain réside dans une nouvelle classe de systèmes d’intelligence artificielle capables de résoudre des problèmes autrefois jugés trop complexes pour des solutions automatisées.
Conclusion
Des projets o1 et o3 d’OpenAI aux dernières recherches chinoises, un schéma clair se dégage : le calcul en temps réel est la nouvelle frontière : En combinant l’initialisation de politiques, des récompenses soigneusement élaborées, des stratégies de recherche sophistiquées et l’apprentissage continu, les modèles d’IA peuvent se comporter davantage comme de véritables résolveurs de problèmes que comme des moteurs de mémorisation par cœur.
Alors que nous entrons de plain-pied dans l’ère de la découverte, nous pouvons nous attendre à de nouvelles possibilités d’interaction de l’IA avec le monde, avec un raisonnement d’un niveau autrefois considéré comme impossible. Qu’il s’agisse de résoudre des questions scientifiques complexes, de contribuer à des projets créatifs ou d’aider les entreprises à automatiser des tâches, les modèles « pensants » promettent de transformer l’IA d’un simple autocomplétion en un véritable partenaire de l’innovation.
L’avenir, semble-t-il, n’appartient pas seulementà des modèles plus grands, mais aussi à des modèles plus intelligents– des machines qui savent s’arrêter, reconsidérer et explorer de multiples voies à la recherche de quelque chose de nouveau. Cela prouve ce que de nombreux éducateurs ont toujours pensé : prendre son temps pour réfléchir est le meilleur moyen d’obtenir la bonne réponse au bout du compte. Et il s’avère que c’est tout aussi vrai pour l’IA que pour nous, les humains.
Par Jérémy BRON, Directeur IA, Silamir Group
Sources
-
- Test Time Compute (2024, December 13). Cloud Security Alliance Blog. Retrieved from https://cloudsecurityalliance.org/blog/2024/12/13/test-time-compute#
-
- Zeng, Z., Cheng, Q., Yin, Z., Wang, B., Li, S., Zhou, Y., Guo, Q., Huang, X., & Qiu, X. (2024, Dec 18). Scaling of Search and Learning: A Roadmap to Reproduce o1 from Reinforcement Learning Perspective. Fudan University & Shanghai AI Laboratory. Retrieved from https://arxiv.org/pdf/2412.14135
-
- OpenAI Scale Ranks Progress Toward ‘Human-Level’ Problem Solving (2024, July 11). Bloomberg. Retrieved from https://www.bloomberg.com/news/articles/2024-07-11/openai-sets-levels-to-track-progress-toward-superintelligent-ai?embedded-checkout=true



